Intégration applicative sous Citrix : de la qualification métier à la mise en production
Guide des bonnes pratiques : de la qualification métier à la mise en production


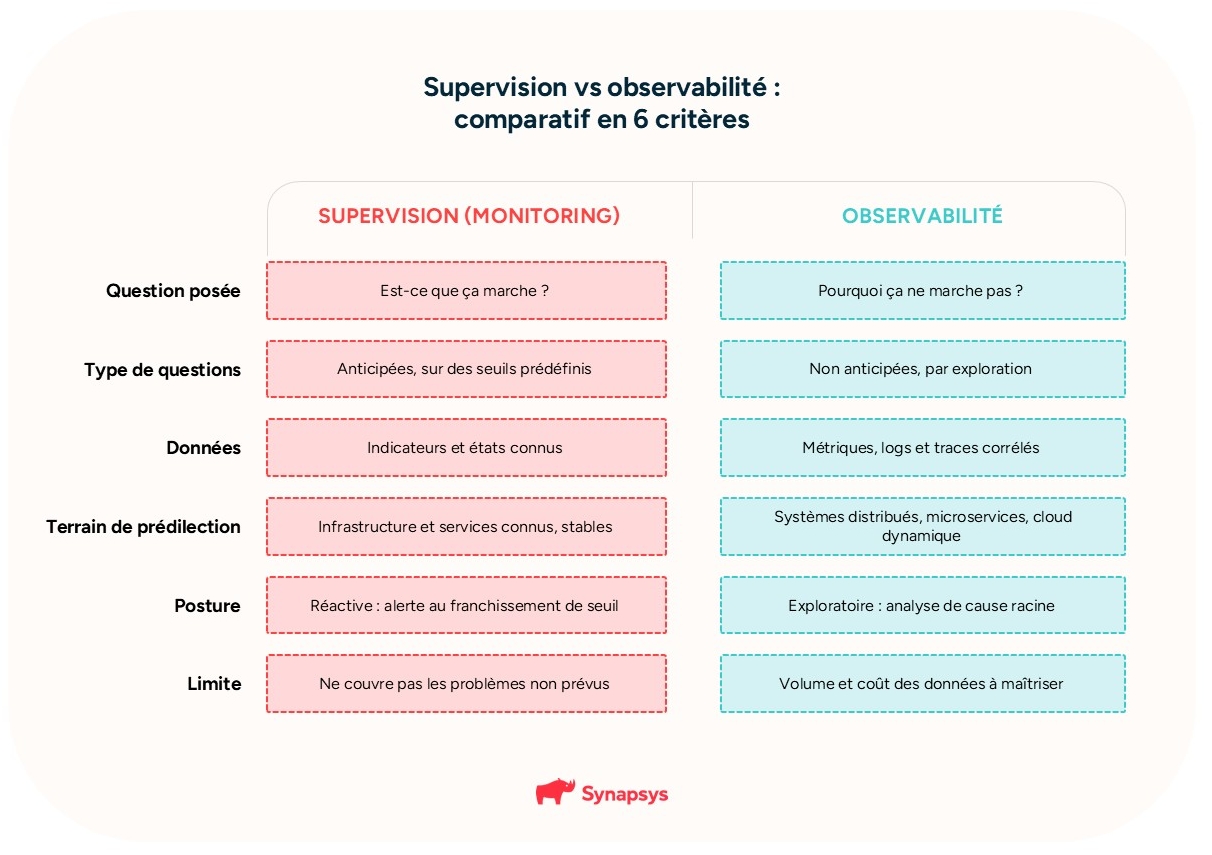
La supervision (monitoring) surveille un périmètre connu du système d’information et alerte quand un seuil est franchi : elle dit qu’un problème existe.
L’observabilité va plus loin : à partir des sorties du système (métriques, logs, traces), elle permet de comprendre pourquoi un problème survient, y compris pour des questions que personne n’avait anticipées.
Les deux sont complémentaires, et le bon outil dépend de votre architecture.
Cet article clarifie les différences, détaille les trois piliers de l’observabilité, explique pourquoi il ne faut pas choisir entre les deux, et donne des repères concrets pour sélectionner l’outil adapté à votre SI.
La supervision consiste à surveiller et contrôler un périmètre défini du SI : serveurs, réseaux, applications, services. Elle mesure des indicateurs connus (disponibilité, charge CPU, espace disque, latence), les compare à des seuils prédéfinis et déclenche une alerte quand un seuil est franchi.
Sa logique est celle des « known unknowns » : on sait à l’avance ce que l’on veut surveiller, et l’outil répond aux questions que l’on a anticipées.
C’est une approche éprouvée, indispensable, et souvent suffisante pour une infrastructure relativement stable. Sa limite apparaît quand le problème n’avait pas été prévu : un tableau de bord ne montre que ce qu’on lui a demandé de montrer.
Face à un incident inédit dans un environnement complexe, la supervision dit qu’il se passe quelque chose, mais pas toujours quoi ni pourquoi.
L’observabilité est la capacité à comprendre l’état interne d’un système à partir des données qu’il produit, sans avoir à le modifier ni à anticiper toutes les questions.
Plutôt que de se limiter à des indicateurs prédéfinis, elle collecte des signaux riches (métriques, logs, traces) et permet de les explorer et de les corréler pour répondre à des questions non prévues.
Cette approche exploratoire prend tout son sens dans les architectures distribuées : microservices, conteneurs, cloud dynamique, où un incident naît rarement d’un seul composant mais d’une chaîne d’événements (appel d’API instable, ralentissement entre services, incident intermittent difficile à reproduire).
Là où la supervision répond aux questions anticipées, l’observabilité permet de répondre à celles que l’on n’avait pas vues venir, et de passer de « c’est lent » à « la cause racine est X » en minutes plutôt qu’en heures.
Un repère simple : la supervision est nécessaire pour savoir qu’un problème existe ; l’observabilité est nécessaire pour comprendre pourquoi, quand le problème dépasse un composant isolé. L’une n’annule pas l’autre.
L’observabilité repose sur trois types de données télémétriques, complémentaires. Chacune apporte une perspective ; leur vraie puissance vient de leur corrélation.
| Pilier | Ce qu’il apporte | Le signal |
| Métriques | Tendances et anomalies agrégées dans le temps (latence, trafic, taux d’erreur) | Le « quoi » : c’est lent |
| Logs | Enregistrements détaillés des événements et leur contexte | Le « pourquoi » : l’erreur exacte |
| Traces | Parcours d’une requête à travers les services d’un système distribué | Le « où » : quel service bloque |
La corrélation est la clé. Un identifiant unique (le trace_id), généré à l’entrée de chaque requête et propagé à travers les services, relie les trois piliers :
C’est ce lien qui transforme trois outils séparés en un système de diagnostic intégré. Certaines plateformes ajoutent un quatrième signal (le profiling de code ou les événements).
Un point de vigilance budgétaire : la cardinalité des données, c’est-à-dire le nombre de valeurs uniques, est le principal facteur de coût ; les identifiants illimités ont leur place dans les logs, pas dans les étiquettes de métriques.

Opposer les deux est une erreur fréquente. La supervision reste la couche de base : elle détecte et alerte sur le périmètre connu, au meilleur coût. L’observabilité s’ajoute lorsque la complexité l’exige, pour investiguer ce que la supervision ne peut pas expliquer.
La plupart des organisations matures combinent les deux : une supervision solide de l’infrastructure et des services, complétée par une observabilité sur les applications distribuées et critiques.
La bonne question n’est donc pas « supervision ou observabilité ? », mais « quel niveau d’observabilité ajouter, où, et à quel coût ? ».
Une infrastructure simple et stable peut se contenter d’une supervision bien réglée ; un SI cloud-native fait de dizaines de microservices a besoin d’observabilité pour rester diagnosticable.
A lire aussi : Observabilité IT : comment passer d’un centre de coûts à un levier de gouvernance intelligente
Le bon outil dépend de votre architecture, de la maturité de vos équipes et de votre budget. Quelques critères de décision avant de regarder les marques :
Le marché se répartit en trois grandes familles, qui ne s’adressent pas aux mêmes contextes ni aux mêmes équipes.
Le bon choix ne dépend pas de la notoriété de l’outil, mais de l’adéquation avec votre architecture, vos ressources internes et votre modèle de coût. Une organisation peut très bien combiner deux familles : une supervision d’infrastructure pour le socle, et une solution d’observabilité pour les applications critiques.

Quelques repères de marché : Zabbix (2001) et Centreon (2005, éditeur français à forte communauté) sont des références de la supervision open source.
Côté observabilité :
Dans tous les cas, un pipeline OpenTelemetry en amont reste le meilleur moyen de garder la main sur ses données et d’éviter l’enfermement.
Certaines erreurs reviennent systématiquement lors de la mise en place d’une stratégie de supervision ou d’observabilité, souvent coûteuses, et toujours évitables. En voici les six principales :
La supervision dit qu’un problème existe (sur un périmètre prévu) ; l’observabilité permet de comprendre pourquoi, y compris pour des problèmes non anticipés, en corrélant métriques, logs et traces.
Non. La supervision reste la couche de base pour détecter et alerter au meilleur coût. L’observabilité s’ajoute pour investiguer la complexité des systèmes distribués. Les organisations matures combinent les deux.
Les métriques (tendances et anomalies), les logs (le détail des événements) et les traces (le parcours d’une requête entre services). Leur corrélation via un identifiant commun est ce qui crée la valeur.
OpenTelemetry (OTel) est un standard ouvert d’instrumentation, neutre vis-à-vis des fournisseurs. Il permet d’instrumenter une fois et d’envoyer les données vers la plateforme de son choix, ce qui limite la dépendance et facilite les migrations.
Cela dépend de la maturité de l’équipe et du budget. L’open source (Grafana, Prometheus, Zabbix) offre flexibilité et maîtrise des coûts mais demande des compétences ; le SaaS (Datadog, Dynatrace) réduit la charge d’exploitation à un coût plus élevé qui croît avec le volume.

Articles similaires
Guide des bonnes pratiques : de la qualification métier à la mise en production
OpenShift vs Kubernetes : la bonne plateforme est celle que votre équipe peut réellement opérer en production.
Et si maîtriser les coûts cloud commençait par mieux comprendre ce qui se passe réellement dans vos systèmes ? Entre...