

L’IA fait aujourd’hui partie intégrante de notre quotidien. Nous l’utilisons dès le réveil via nos applications favorites comme Facebook Instagram, Twitter, etc.
Plus tard dans la journée, pour connaitre le chemin le plus court pour nous rendre sur notre lieu de rendez-vous, choisir un restaurant qui nous aura été préalablement suggéré en fonction de nos habitudes.
Et finalement, une fois la journée terminée, pour écouter de la musique, donner des ordres à notre assistant personnel connecté ou encore regarder nos vidéos favorites qui nous auront été suggérées.
L’Intelligence Artificielle : Définition
Mais pour commencer, quelle serait une définition de l’intelligence artificielle ?
Cédric Villani, le défini comme cela : L’intelligence artificielle, c’est toute technologie informative qui permet de résoudre des problèmes complexes qu’on aurait cru réservés à l’intelligence humaine.
Dans un futur proche, cette IA pourra être utilisée dans: le secteur de l’automobile pour conduire des véhicules autonomes, de la santé pour aider les professionnels à poser un diagnostic, ou dans beaucoup d’autres domaines pour analyser des quantités de données toujours plus importantes et prédire des modèles et anticiper les résultats.
La source
La source, c’est-à-dire la matière première utilisée par les algorithmes d’IA est la donnée. Elle peut prendre plusieurs formes et venir de sources multiples et variées.
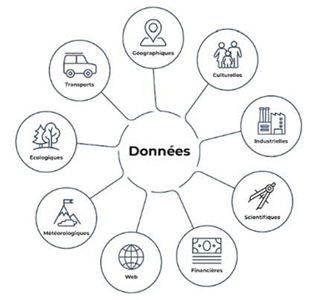
Les données alors récupérées sont stockées et la quantité massive qu’elles représentent forment ce que l’on appelle le Big Data.
Des métiers ont aujourd’hui vu le jour autour du traitement de ces données et de leur analyse. Cette discipline s’appelle la Data science. L’objectif principal est alors de créer des modèles d’analyse des données et de faire apparaître des corrélations.
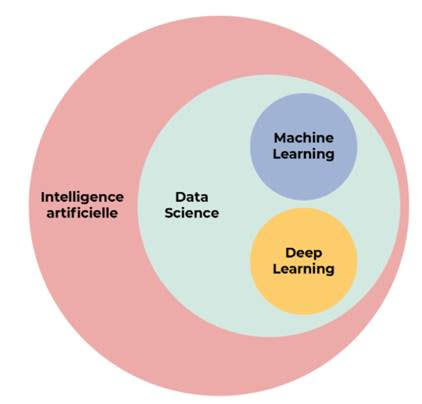
Pour aller plus loin, ces analyses peuvent être automatisées via 2 disciplines spécifiques de l’IA, le Machine learning et le Deep learning.
Le machine learning est un sous ensemble de l’IA et au même titre, le deep learning est un sous ensemble du machine learning.
Le principe du machine learning est d’apprendre à un programme informatique à réaliser une tâche et à l’automatiser tout en lui permettant de s’améliorer et de continuer à apprendre au cours de ses analyses.
Le deep learning quant à lui, s’appuie sur la mise en place d’un réseau neuronal. Chaque neurone sera responsable de réaliser un calcul pour fournir une donnée de sortie spécifique.
Vers la fin de l’humanité ?
Alors oui, lorsque l’on parle de l’IA, nous pensons rapidement à tous les films apocalyptiques tels que Terminator ou I-Robot dans lesquels, la machine prend le pas sur l’homme et cherche à l’anéantir.
En réalité, nous sommes encore très loin de ces scénarios de fin du monde.
Tout d’abord car l’IA et la robotique ne sont pas des synonymes. Il est possible d’intégrer de l’IA dans un robot mais les tâches qu’il réalise aujourd’hui sont pour la majorité séquentielles et donc ne s’appuient pas sur de l’IA mais aussi parce que les algorithmes qui existent aujourd’hui ont « appris à apprendre » et sont basés sur des formules mathématiques. En résumé, l’avènement des machines n’est pas encore pour demain et même si l’IA a un potentiel immense, elle reste aujourd’hui un programme informatique non motorisé sans sens critique et qui doit être programmée pour apprendre.
Quels enjeux pour l’avenir ?
L’IA vous l’aurez compris, a un potentiel extraordinaire si tant est qu’elle soit utilisée à bon escient. Elle permettra d’apporter une aide non négligeable aux médecins lors de l’analyse de données d’imagerie médicale, d’anticiper certaines catastrophes naturelles de façon beaucoup plus précise et donc de prévoir de manière plus efficace les ressources et les réponses à apporter.
De façon plus générale, l’IA pourra devenir une aide à la décision et à l’anticipation. Attention toutefois à ne pas se reposer entièrement sur les suggestions de ces algorithmes qui bien qu’intelligents ne doivent pas à terme remplacer l’humain et son esprit critique. L’Intelligence Artificielle est un outil et non pas une fin, gardons cela en tête.
Le devenir de nos données
Et les données dans tout ça ? La collecte des données, le devenir des données utilisées pour entrainer les algorithmes et à terme l’utilisation des données collectées par tous les acteurs du numérique est une question centrale.
D’où viennent ces données ? Quelles sont les données qui sont transmises ? Sont-elles monétisées ? Gardons simplement une chose en tête, une donnée qui se trouve sur internet, n’est plus une donnée qui nous appartient. Bien qu’elle reste une donnée personnelle, elle devient accessible et utilisable. Reste à savoir comment cette donnée sera traitée. Et sur ce point, la législation est assez jeune. La CNIL en France et la RGPD en Europe sont des régulateurs qui mettent petit à petit en place des verrous légaux pour limiter l’usage de ces données. Cependant, les acteurs du numérique tels qu’Amazon, Google, Twitter, Facebook, Microsoft etc. pour ne citer que les plus importants et les plus connus, ne sont pas nécessairement soumis aux législations locales puisque nos données transitent et peuvent être hébergées sur des serveurs qui ne sont pas sur le sol français et donc pas soumis au lois françaises/européennes.
La meilleure parade aujourd’hui consiste à contrôler les données que vous mettez en ligne et que vous partagez sur les réseaux et sur internet, sans toutefois tomber dans la paranoïa, auquel cas, il ne vous reste plus qu’à vous débarrasser de votre téléphone, ordinateur et de votre connexion internet.
Quid de l’environnement ?
Cette question peut paraître étonnante mais il faut savoir que les ressources nécessaires pour faire tourner un programme d’IA sont extrêmement importantes. En effet, la puissance de calcul pour réaliser les analyses est très consommatrice d’électricité. A terme, cette composante devra impérativement être prise en compte dans les projets d’IA puisque les ressources ne seront pas infinies.
Suivre un projet d’Intelligence Artificielle
Un projet d’IA se déroule selon des phases bien spécifiques décrites ci-dessous.
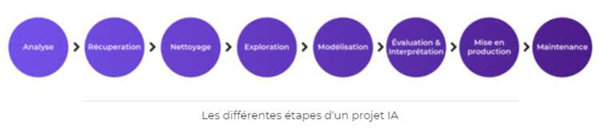
Pour que ce projet se déroule correctement, il faudra faire intervenir les profils suivant:
· Experts métiers : qui auront la connaissance du secteur auquel s’applique le projet et qui pourront apporter les données nécessaires et pointer les incohérences
· Experts du numérique : Développeur, Architecte logiciel
· Spécialistes de l’IA : Expert en IA et Data scientists
· Gouvernance : Chef de projet, Délégué à la protection des données et tout autre profil qui apportera sa compétence au projet
Vient ensuite le cadrage du besoin puis la réalisation et le traitement des données.
Il faudra commencer par nettoyer les données mises à disposition. C’est-à-dire, vérifier que les données fournies ne sont pas incohérentes, qu’elles ne présentent pas d’anomalies et qu’il ne manque pas certaines données.
Vient ensuite la phase d’exploration. L’objectif est de comprendre les données et d’essayer d’en tirer des observations et des corrélations. Des outils de visualisation des données tels qu’Excel ou Power BI entre autres peuvent être utilisés pour cela.
Modéliser les données. Une fois choisi l’outil d’IA qui sera utilisé et le modèle mathématique à appliquer à votre jeu de données, vous pourrez commencer à modéliser vos données et à essayer d’effectuer des prédictions grâce à votre système.
Dernière étape, l’évaluation et l’interprétation des données. Les résultats fournis par votre IA devront être étudiés, en les appliquant par exemple à un jeu de données existant que vous n’aurez pas utilisé pour vos tests afin de valider la prédiction.
La mise en production. Une fois le modèle validé, il ne reste plus qu’à l’utiliser en condition réelle et à vérifier que les prédictions de l’IA permettent bien de répondre aux objectifs fixés initialement.
Pour aller plus loin
Il existe différentes méthodes d’apprentissage pour l’IA.
Le Machine learning permet à un programme d’apprendre automatiquement et de faire évoluer ses résultats. Cet apprentissage peut être fait de 3 façons:
· Apprentissage supervisé, dans ce cas, on donne à l’algorithme le résultat attendu pour un certain échantillon de données, puis, on lui soumet de nouvelles données. Il devra se baser sur ce qu’il a déjà appris pour traiter les nouvelles données
· Apprentissage non supervisé, ici, on laisse l’algorithme effectuer des regroupements puis on valide ou non le résultat de ces regroupements
· Apprentissage par essai/erreur, dernière méthode, l’algorithme apprend au fur et à mesure des résultats. Il teste à chaque réponse si celle-ci est correcte ou non puis s’adapte en fonction du résultat. L’algorithme apprend par « tâtonnement »
Le Deep Learning est une sous discipline du machine learning et utilise un réseau de neurone artificiel.
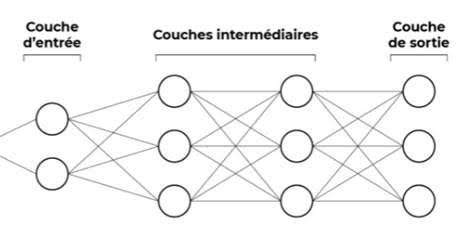
Dans ce cas, les données de sortie attendues sont identifiées dès le départ. On introduit alors une donnée en entrée et chaque couche intermédiaire effectuera un calcul mathématique pour lequel elle a été programmée avant de la transmettre à la couche suivante jusqu’à la couche de sortie qui devra donner le résultat. En fonction de la véracité du résultat, le réseau adaptera ses calculs pour optimiser ses réponses et donner le bon résultat à coup sûr.
Bilan
J’espère que cet article vous aura permis d’y voir un peu plus clair dans ce vaste univers qu’est l’Intelligence Artificielle et de déconstruire les idées reçues qui ont encore la vie dure. Non l’IA n’est pas encore prête à remplacer l’homme mais on peut déjà identifier des avancées significatives grâce à elle.
Des questions éthiques sont posées et devront continuer à l’être. Par exemple la notion de biais qui peuvent être introduits dans les algorithmes si les données en entrée ne sont pas elles même neutres. Or à ce jour, les algorithmes d’IA ne sont pas capables de discernement et d’esprit critique. C’est donc l’homme qui doit être garant de la qualité et de la neutralité des données d’apprentissage. A qui la faute donc si une Intelligence Artificielle aura appris à favoriser certaines personnes ou un certain type de réponse car les données d’entrée lui auront appris cela ? J’ai mon avis, je vous laisse vous faire le vôtre. Il sera donc indispensable de mettre en place des gardes fous en particulier lorsque ces données traiteront de l’humain.
Dernier point, il faudra que les utilisateurs soient capables de conserver un esprit critique vis-à-vis des résultats et ne pas se reposer sur la machine. Nous sommes de plus en plus confrontés à ces outils qui facilitent notre prise de décision et notre vie de tous les jours. Alors prenons le bon chemin, utilisons cela comme ce que c’est, un outil qui nous permettra de libérer du temps pour d’autres tâches à plus forte valeur ajoutée et que l’IA « ne saura pas » traiter comme les relations humaines et investir notre temps gagné dans des actions plus utiles pour le bien commun. Si ce sujet vous intéresse, je vous conseil de suivre cette formation d’Openclassrooms dont je me suis inspiré pour écrire cet article.