

Dans un article précédent, nous avons parlé des bases d'AWS Bedrock et comment il peut être un outil utile pour vous permettre d'extraire la puissance de l'IA en quelques étapes faciles.
Dans ce post, nous allons explorer l'IA RAG car c’est un choix populaire par les entreprises, étant donné la facilité / rapidité de mise en œuvre et à expérimenter. Il permet en effet d'adapter un système en quelques clics, en modifiant les données auxquelles il a accès. Le fine tuning et le RAG peuvent également fonctionner ensemble, ce que nous explorerons plus en détail prochainement.
IA : le RAG transforme l'accès aux bases de connaissance
Il ne fait aucun doute que l'IA Générative a eu un impact conséquent sur les entreprises, créant de la valeur plus rapidement que jamais et explorant des possibilités qui n'étaient tout simplement pas possibles (ou pratiques) auparavant. La France ne fait pas exception puisque nous avons vu des entreprises françaises comme HuggingFace et Mistral prospérer dans cet espace. L'un des cas d'utilisation qui a été le plus transformateur dans toutes les industries est l'exploration des bases de connaissances.
Une base de connaissances se définit comme une agrégation de connaissances, qui peut se présenter sous la forme de PDF, fichiers audio, images, vidéos, FAQ, guides pratiques, conseils de dépannage, informations sur les produits, tutoriels, politiques internes, documentation sur la conformité, ou toute information propre à l’entreprise. Il est généralement difficile de rendre ce type d'information plus utile en raison de sa dimension, du moins pour un humain, mais le RAG et l'IA sont venus résoudre ce problème.
L'IA Générative a été rendue populaire par ChatGPT qui est un LLM (large langage model), et bien que cette application n'ait accès qu'aux données sur lesquelles elle a été entraînée et qu'elle réponde en fonction du texte que nous lui donnons, nous pouvons également aller plus loin en construisant des systèmes qui utilisent plus de données que nous leur donnons, et ainsi les rendre plus utiles pour nos cas d'utilisation spécifiques.
Au cœur de tout cela se trouvent les modèles fondamentaux. Ces modèles construits par des entreprises comme OpenAI, Meta, AWS, Mistral et Anthropic nécessitent des millions de dollars et des mois pour être entraînés, mais nous pouvons les spécialiser sur nos cas grâce à deux techniques : le fine-tuning et le RAG.

Qu'est-ce que le RAG dans l'IA ?
Retrieval Augmented Generation (ou RAG) est une technique puissante qui améliore la précision et la pertinence des réponses des LLM en récupérant des informations pertinentes à partir de sources de données externes.
En convertissant les documents et les requêtes des utilisateurs en vecteurs, l'IA RAG permet d'effectuer des recherches de similarité sémantique pour trouver les textes les plus pertinents, qui sont ensuite utilisés pour compléter la réponse du LLM. Sans RAG, nous avons un flux de travail qui semble aussi simple que celui-ci :

Afin d'utiliser le RAG pour résoudre certaines limitations de LLM, nous devons effectuer quelques étapes supplémentaires et ajouter des systèmes additionnels à notre architecture :
- Une base de connaissances
- Un modèle d'embedding
- Un modèle de recherche
- Une base de données vectorielle
Nous aurons donc quelque chose comme ceci :
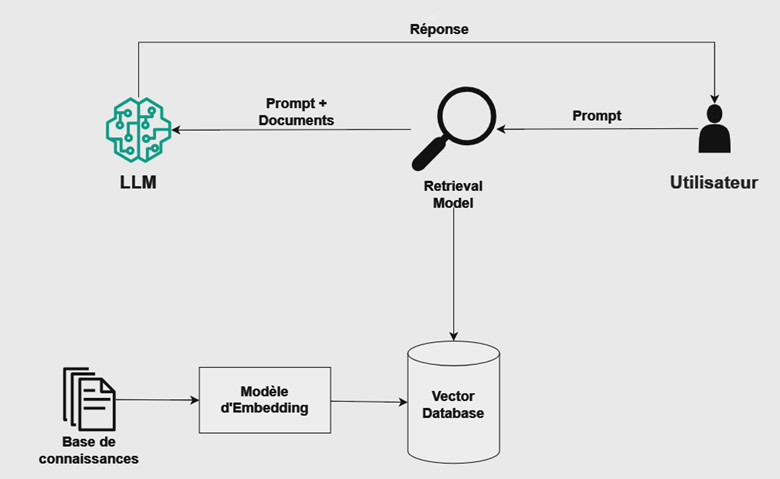
Pour simplifier, nous devons d'abord faire passer nos documents par un modèle d'incorporation car le modèle de recherche ne comprend pas le texte pur. Le modèle d'intégration est chargé de transformer le texte de la base de connaissances en vecteurs, c'est-à-dire en une liste de nombres qui représentent le texte d'une manière compréhensible pour le modèle de recherche.
Une fois que nous avons les vecteurs pour un texte donné, nous les stockons dans une base de données vectorielle (dans notre cas, nous utiliserons AWS OpenSearch, un service géré qui nous permet de stocker des vecteurs et de les récupérer facilement), car il serait très coûteux et fastidieux d'exécuter le modèle d'incorporation chaque fois que nous voulons interroger notre base de connaissances.
Avec une base de données vectorielle remplie de nos données, nous pouvons envoyer notre message au modèle de recherche qui transformera notre message en vecteurs et le comparera aux données de la base de données vectorielle. Pour ce faire, ces systèmes utilisent généralement la similitude cosinus qui est une fonction mathématique simple qui compare deux vecteurs pour voir s'ils sont proches dans l'espace d'intégration, et si c'est le cas, cela signifie qu'ils sont similaires et peuvent nous aider à répondre à notre question.
Si c'est le cas, cela signifie qu'ils sont similaires et que cela peut nous aider à répondre à notre question :
Nous envoyons cette question au modèle : « Quand la société Y a-t-elle été fondée ? »
Le modèle de recherche comparera ce texte à de nombreux vecteurs stockés dans la base de données vectorielles, trouvera des vecteurs similaires et obtiendra leur texte, qui pourrait ressembler à ceci : « ...la société Y a été fondée en 2003 ».
Nous pouvons ajuster le nombre de textes qu'il obtiendra de la base, de sorte que nous pouvons dire, par exemple, que nous voulons qu'il récupère les 5 morceaux de texte les plus similaires trouvés et qu'il les envoie au modèle.
Ainsi, le modèle disposera de toutes les données dont il a besoin pour répondre à notre question. Ce processus peut sembler compliqué et lent, mais il se déroule automatiquement et en quelques millisecondes ou secondes.
Orchestration avec LangChain
Afin de contrôler tout cela de manière plus organisée, nous pouvons utiliser un outil d'orchestration. Dans notre cas, nous avons utilisé LangChain, une bibliothèque Python qui comporte de nombreux modules permettant de se connecter à différent modèles et contrôler finement le système et ses résultats.
Le code de cette démo où LangChain est utilisé est disponible sur Github.
Démonstration du système RAG
Pour démontrer un système RAG, nous avons créé une application de questions réponses pour aider les utilisateurs à découvrir s'ils peuvent bénéficier d'une aide financière du gouvernement français pour rénover leurs maisons, en fonction de leur localisation et d'autres données. Nous avons alimenté le modèle avec un document du gouvernement datant de 2024.
Le processus diffère d'un cas d'utilisation à l'autre. Il est donc nécessaire d'explorer et de modifier les paramètres, les données, les méthodes d'extraction, etc. afin qu'il fonctionne bien pour chaque application. AWS Bedrock facilite la modification des modèles et l'ajout de nouveaux documents à notre base de connaissances, ce qui accélère le passage du concept à l'application déployée. Dans notre cas, nous avons expérimenté principalement avec Llama 3.
Conclusion sur le RAG et l'IA
En conclusion, l'utilisation d'AWS Bedrock et de la technique RAG peut considérablement améliorer la façon dont les entreprises extraient et utilisent les informations de leurs vastes bases de connaissances. En intégrant des modèles fondamentaux à des systèmes spécialisés tels que des modèles d'embedding, des extracteurs et des bases de données vectorielles, les entreprises peuvent créer des solutions pilotées par l'IA adaptées à leurs besoins et leurs données d’entreprise.
À mesure que nous continuons d'explorer et d'affiner ces techniques, le potentiel de transformation de divers secteurs par l'IA devient de plus en plus évident. Que vous traitiez des PDF, des fichiers audios ou toute autre forme de documentation, la combinaison d'AWS Bedrock et de RAG offre un ensemble d'outils puissants pour rendre vos données plus accessibles et exploitables.
Restez à l'écoute pour les prochains articles dans lesquels nous approfondirons le fine-tuning et d'autres techniques avancées afin d'optimiser davantage les applications d'IA pour vos besoins commerciaux. N'hésitez pas à nous contacter pour nous faire part des projets que vous souhaitez mettre en œuvre avec l'IA.