

Si tout était parfait, aurions-nous besoin de contrôler et de surveiller notre SI et ses applications… ?
Peut-être que non mais la réalité nous rappelle souvent que, quelque soit le niveau d’excellence des équipes et de leurs outils technologiques, la perfection n’existe pas !
Pour pallier cette non-perfection, il nous faut trouver des moyens d’être conscients des défauts, des mal fonctions, des événements imprévus : il nous faut du feedback !
L’un des piliers du mode de travail DevOps est justement le feedback : qu’il soit technique ou humain (retours de sondes, retour d’expérience utilisateur…)
Cette partie technique évolue constamment et va plus loin que le « simple » monitoring.
C’est là qu’entre en jeu l’observabilité ; nous verrons ce qu’est ce principe et ses apports dans le cadre de développement d’applications ou dans le cadre plus large du SI, surtout au niveau de la « vie opérationnelle ».
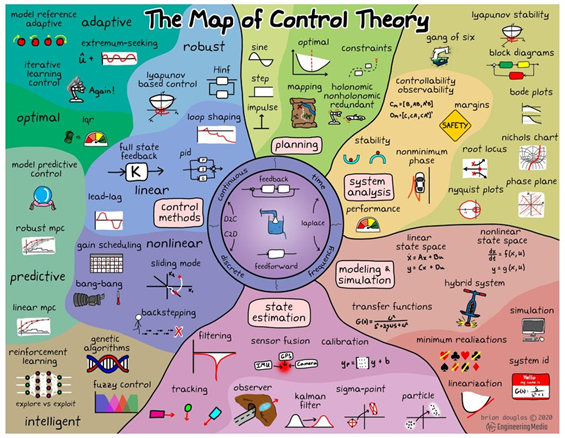
La théorie du contrôle
L’observabilité s’inspire de la théorie du contrôle, utilisée principalement dans le monde scientifique :
La théorie du contrôle est une théorie mathématique permettant, de déterminer des lois de guidage, d’action, sur un système donné.
Un système de contrôle est un système dynamique sur lequel on peut agir au moyen d’une commande ou contrôle.
Autrement dit, c’est contrôler les états internes d’un système en contrôlant les entrées extérieures.
On rencontre dans la pratique de très nombreux problèmes de contrôle, dans toutes les disciplines : par exemple garer sa voiture, piloter un avion ou un satellite vers une orbite géostationnaire, optimiser les flux d’information dans un réseau, coder et décoder une image numérique ou encore pour avoir de la vaisselle propre ! ?
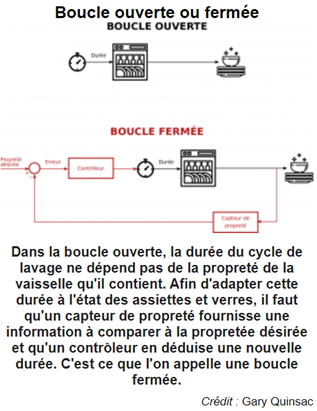
Le problème de contrôlabilité est d’amener le système d’un état initial donné à un certain état final, en respectant éventuellement certaines contraintes.
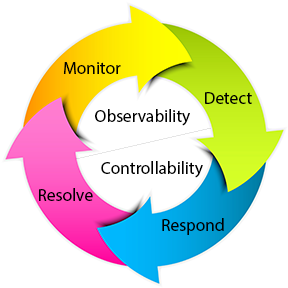
La contrôlabilité et l'observabilité sont les principaux problèmes dans l'analyse d'un système avant de décider de la meilleure stratégie de contrôle à appliquer, ou s'il est même possible de contrôler ou de stabiliser le système.
L'observabilité est plutôt liée à la possibilité d'observer, par des mesures de sortie, l'état d'un système. Si un état n'est pas observable, le contrôleur ne pourra jamais déterminer le comportement d'un état non observable et ne pourra donc pas l'utiliser pour stabiliser le système.

Mieux comprendre l’observabilité
Une définition large :
En tant que philosophie, l'observabilité est notre capacité à savoir et à découvrir ce qui se passe dans nos systèmes. En pratique, cela signifie ajouter de la télémétrie à nos systèmes afin de mesurer les changements et de suivre les flux de travail. (The newstack.io)

Simplement, l’observabilité est votre niveau de compréhension des systèmes complexes que vous gérez.
Comme le note Gartner, l'observabilité n'est pas seulement le résultat de la mise en œuvre d'outils avancés, mais une propriété intégrée d'une application et de son infrastructure. Les architectes et développeurs qui créent le logiciel doivent l’intégrer dans leurs conceptions. Ensuite, les équipes peuvent exploiter et interpréter les données observables.
Gartner caractérise l'observabilité comme l'évolution des capacités de monitoring traditionnelles en réponse aux demandes des technologies cloud natives.
Contrairement aux approches conventionnelles de la visibilité, l'observabilité consiste à examiner la pile logicielle complète - quelle que soit sa complexité - pour suivre chaque fonction et demande dans le contexte complet de son infrastructure sous-jacente et de ses utilisations.
La relation entre monitoring et observabilité
Le monitoring est un composant essentiel, un sous-ensemble de l'observabilité .
Le monitoring (un verbe) est axé sur les symptômes. Cela vous indique que quelque chose ne va pas.
L'observabilité (un nom) est une propriété de votre approche qui vous permet de vous demander pourquoi.
Le monitoring repose sur la connaissance à l'avance des signaux que vous souhaitez surveiller (ce sont vos « inconnues connues »).
Le monitoring « conventionnel » ne peut pas résoudre ce problème du « pourquoi ».Il ne peut suivre que les inconnues connues. (Source : Blog newrelic.com)

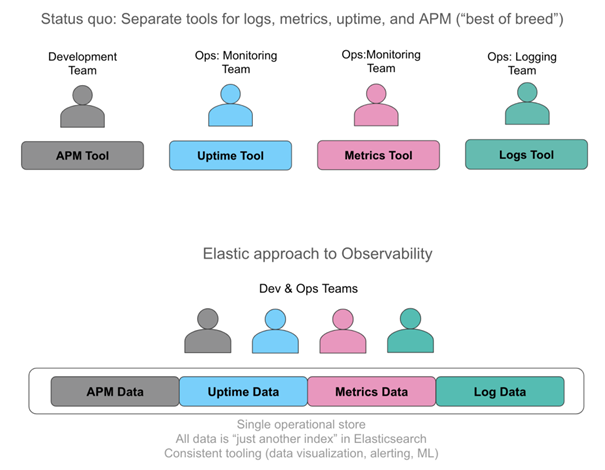
L’observabilité est donc obtenue par l’assemblage de plusieurs composants (APM, monitoring, Logs…)
Quels sont les inputs techniques de l’observabilité ?
Ce sont les types de données qu'un système doit produire pour être observables.
- Métriques : il s'agit d'une représentation numérique de données collectées à intervalles réguliers dans une série chronologique. Les données de séries chronologiques numériques sont faciles à stocker et peuvent être interrogées rapidement ; cela aide lors de la recherche des tendances historiques.
- Logs : ils représentent des événements discrets. Les entrées de journal sont essentielles pour le débogage, car elles incluent souvent des traces et d'autres informations contextuelles qui peuvent aider à identifier la cause première des échecs observés.
- Traçage distribué, sur demande ou de bout en bout: ils capturent le flux de bout en bout d'une application à travers le système. Le traçage capture essentiellement à la fois les relations entre les services et la structure du travail à travers le système (traitement synchrone ou asynchrone, relations enfants ou suites).
- Health Checks : ce sont souvent des points de terminaison HTTP personnalisés, des orchestrateurs d'aide, comme Kubernetes, ils sont effectués pour maintenir la bonne santé du système.
(Source : Xenonstack.com)
L’observabilité amène une transversalité de l’approche en assemblant les outils voire même les équipes.
Les métriques qui comptent

La simplicité du système, la représentation perspicace des mesures de performance et la capacité des outils de monitoring continu à identifier les paramètres corrects sont responsables de l'observabilité du système.
Cette combinaison donne les informations nécessaires pour construire une représentation précise des états internes, malgré la complexité inhérente à un système.
L’observabilité et le DevOps
Dans les architectures complexes et distribuées, on peut reposer sur des centaines, voire des milliers de microservices : il devient impossible de prévoir toutes les défaillances possibles.
L’observabilité nous donne la possibilité d’étudier la globalité des composants de l’application (métriques techniques d’infrastructure et applicatifs, remontées de logs, sondes « HealthCheck » des orchestrateurs type Kubernetes …) et en temps réel.
Dans le processus de livraison de logiciels, une activité de surveillance continue augmente la productivité et les performances.
La surveillance continue nous aide à réduire les temps d'arrêt et nous permet de mieux répartir le temps et les ressources.
L'objectif principal de la surveillance continue est d'atteindre une haute disponibilité en minimisant le temps de détection et le temps d'atténuation. (ex : MTTR : Mean Time To Repair)
L'avantage de la surveillance constante est d'automatiser le travail qui était auparavant manuel, répétitif et sujet aux erreurs, ce qui se traduit par une vitesse, une productivité et une évolutivité plus rapides - et l'assurance de configurations standardisées dans les environnements de test, de développement et de production.
L'élimination des erreurs et des bugs réduit la perte de temps et vous permet de déployer des logiciels plus rapidement et de manière plus fiable.
Ce Feedback constant apporte un retour rapide sur les différentes phases de développement d’une application, sur ses performances et ses défaillances éventuelles.
L’observabilité est donc un composant essentiel, incontournable des pratiques DevOps.
L’observabilité et IA / ML
Lorsque le volume d’information, de capteurs d’états, devient trop important il peut être opportun d’utiliser des technologies d’intelligence artificielle et de Machine Learning pour automatiser certaines actions de remédiation.
Gartner : Atteindre la visibilité nécessaire pour trouver des anomalies et identifier de manière fiable leurs effets peut être une tâche bien au-delà des capacités humaines. C'est pourquoi l'intelligence artificielle pour les opérations informatiques (AIOps) est un catalyseur crucial de l'observabilité au sein des architectures cloud natives massives d'aujourd'hui qui s'appuient de plus en plus sur des microservices et des environnements conteneurisés.
Une solution alimentée par l'IA peut rapidement établir et ajuster les performances de base et détecter automatiquement les anomalies dans les systèmes distribués
Il est important de tirer parti des AIOps pour comprendre et réagir plus rapidement aux incidents. Le Machine Learning réduit le bruit d'alerte et vous aide à trouver des informations dans les données.
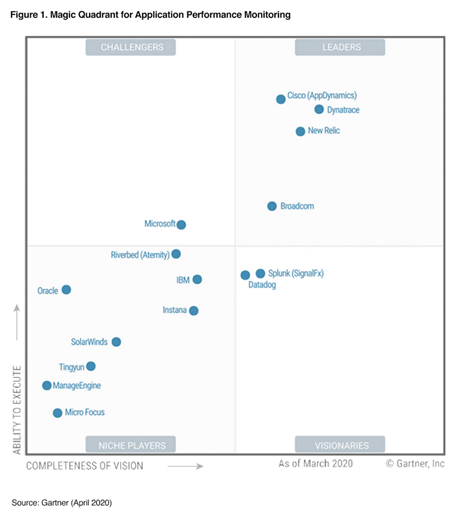
Paysage technologique
Le Magic Quadrant est plus axé sur l’APM mais peut donner une petite idée des acteurs du marché.
Conclusion
Avec une plate-forme d'observabilité ouverte, connectée et programmable, votre entreprise peut bénéficier d’avantages importants :
• Déploiement plus rapide
• Innovation plus rapide
• Moindre coût
• Meilleure optimisation des ressources
Vous obtenez des analyses en temps réel pour comprendre les performances de vos systèmes numériques. : vos équipes passeront moins de temps à dépanner et plus de temps à construire
Ensemble, ces caractéristiques vous permettent de mieux comprendre vos systèmes, les données qu'ils produisent et les expériences client qu'ils permettent. Cela donne à votre entreprise un avantage concurrentiel.
