

DataOps, Le Devops pour la Data ? Plus précisément, c'est l'utilisation des techniques DevOps appliquées au monde des données qui font le DataOps.
Par définition le DevOps n'est pas lié à la data au sens large, cependant, en appliquant des techniques DevOps au Bigdata, nous obtenons de nombreux bénéfices. Voyons plus en détail comment cette association nous amène à la notion de DataOps.
Qu'est-ce que le DevOps ?
Le DevOps combine le développement de logiciels (« Dev ») et les opérations informatiques (« Ops ») pour accélérer la livraison de produits logiciels de haute qualité. Ce manque de cohésion entre le développement et l'informatique a mis à rude épreuve le déploiement de logiciels et a conduit à des produits logiciels retardés, inefficaces ou défectueux.
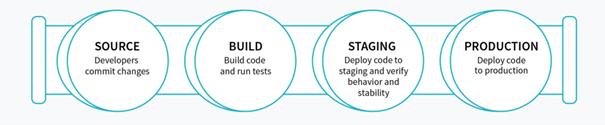
Par conséquent, le DevOps a introduit un ensemble de pratiques de base qui sont désormais des standards dans l'industrie du logiciel. Voici un résumé des bonnes pratiques DevOps :
1. La culture collaborative. Les équipes de développement, d'exploitation et d'assurance qualité doivent aligner les objectifs et coopérer. Dans l’absolu, l’expert métier peut être impliqué dans la démarche.
2. Conçu pour le DevOps. La conception de base pour le DevOps est une architecture modulaire et immuable utilisant des micro-services (dans un monde parfait ! 😊).
3. L’intégration continue (CI). L’intégration des changements au niveau développement doit avoir un impact minimal sur la production.
4. Des tests continus. Intégrant la sécurité. Couvrez tous les pipelines et évitez les goulots d'étranglement.
5. Une surveillance continue. Assurez une couverture complète de tous les pipelines.
6. La livraison continue. Pour pouvoir délivrer de manière continue les changements côté « Dev ».
7. Une infrastructure élastique. Un environnement virtualisé, Cloud et containerisé qui est élastique, codifiable (IAC) et standardisable.
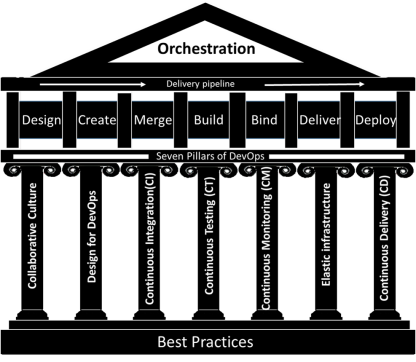
On peut dire que le DevOps est « mûr » pour être appliqué à d'autres domaines technologiques.
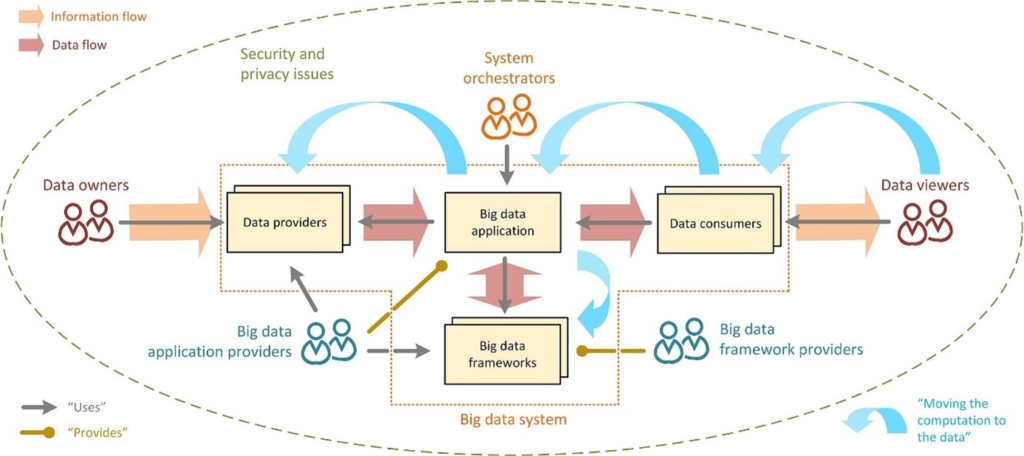
Qu'est-ce que le Big Data ?
Le terme « Big Data » a été initialement fourni par l’institut Gartner : « le Big Data est une forte volumétrie, haute vélocité et grande variété de données qui exigent des techniques innovantes et rentables de traitement d’information pour une meilleure prise de décision ».
Le Big Data est un phénomène caractérisé par une explosion des données, données qui peuvent contenir des opportunités qu’on peut saisir, non pas à l’aide d’approches technologiques traditionnelles, mais à l’aide d’approches technologiques innovantes. C’est en fait une collection sophistiquée et massive d'ensembles de données. L'équipe Big Data comprend entre autres des Data Engineers, des Data Analysts et des data Scientists.
Ainsi, le Big Data permet à une organisation d'obtenir plus de réponses aux requêtes, plus d'informations présentes dans les données. Et obtenir plus de réponses signifie qu'une organisation peut s'attaquer à des problèmes plus complexes voire anticiper des tendances métiers.
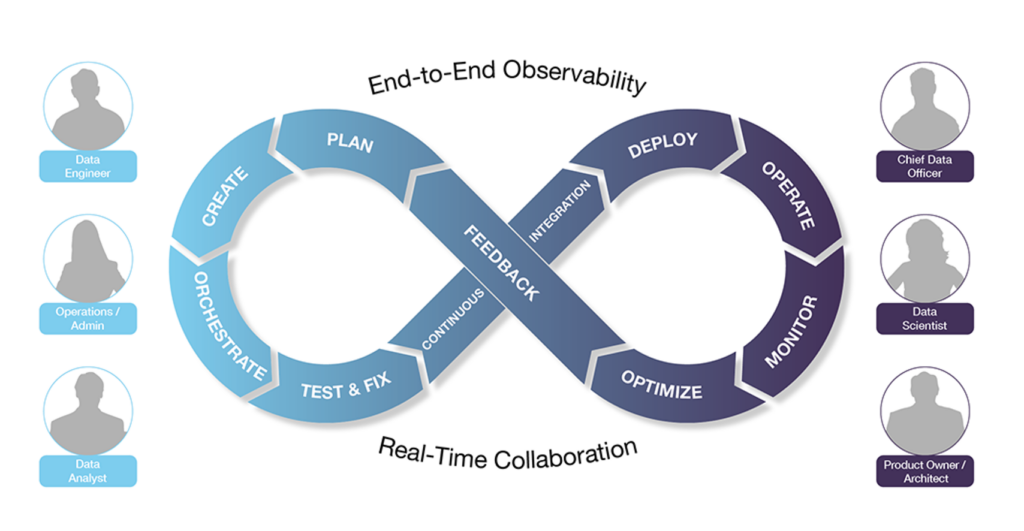
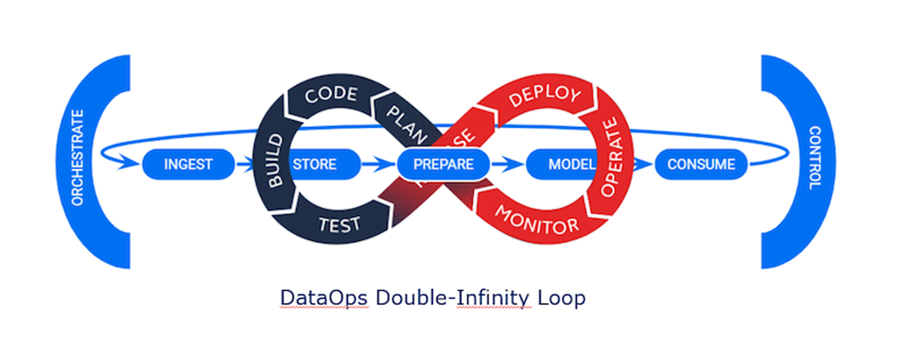
Intégrer les pratiques DevOps à la data : le DataOps
Les projets Big Data peuvent s’avérer difficiles en termes de :
• gestion de grandes quantités de données complexes,
• livraison du projet accélérée afin de rester compétitif sur le marché,
• réponses rapides aux changements.
Sans les pratiques DevOps, tout cela est donc difficile à résoudre. Traditionnellement, les différentes équipes et membres de l'équipe (architectes de données, analystes, administrateurs, etc.) travaillent de manière isolée sur leur part de travail. Or, ce n'est pas favorable pour une livraison rapide.
Contrairement à cette approche, le DevOps rassemble tous les participants du pipeline de livraison de logiciels et supprime les barrières entre eux.
Votre équipe Big Data devient alors transverse, augmente son efficacité opérationnelle et obtient une vision mieux partagée de l'objectif du projet.
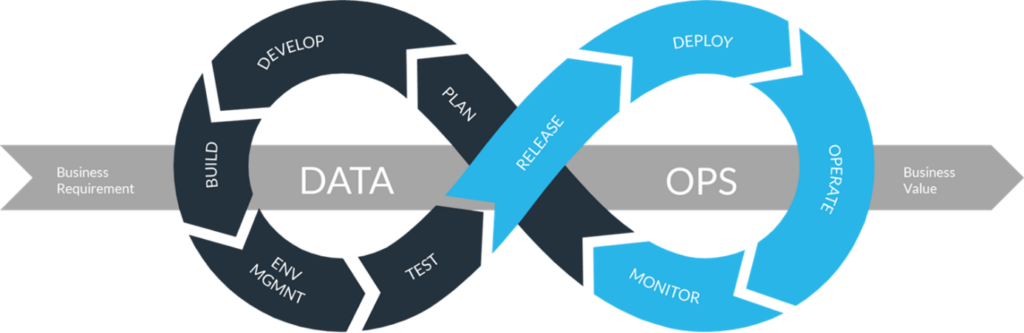
Le DataOps est donc une hybridation intéressante du DevOps, c’est ce qu’on peut appeler une « agglomération ». Le DataOps est une méthodologie qui combine la technologie, les processus, les principes et le personnel pour automatiser l'orchestration des données dans l'ensemble d'une organisation.
C'est pour cette raison que les organisations utilisent le DataOps, afin de fournir des données à la demande de haute qualité en accélérant le développement et le déploiement de workflows de données automatisés.
À mesure que les organisations se développent et que les demandes de données deviennent plus complexes, le DataOps offre un cadre plus flexible pour fournir les bonnes données, au bon moment, à la bonne partie prenante. Il déploie rapidement une nouvelle infrastructure de données pour répondre aux priorités, en constante évolution, de tous les clients.
Le DataOps adopte bon nombre des mêmes principes que le DevOps. Mais tandis que le DevOps automatise le déploiement de logiciels, le DataOps automatise l'orchestration des données : la livraison de bout en bout des données de la source à la cible.
Ces workflows de données automatisent l'ingestion, la transformation et l'orchestration des données.
Le « produit logiciel » sur lequel les équipes DataOps travaillent pendant les sprints est généralement basée sur une infrastructure de données. Dans certains cas, l'infrastructure est en fait traitée comme du code (IAC).
On retrouve les items du DevOps assez facilement :
- Infrastructure : provisioning des jeux de données, déploiement de clusters, installation d'outils et de configurations, politiques de sécurité.
- Ingénierie des données : définir la structure des données, ETL (Extract/Transform/Load), créer des API et fournir une plate-forme de données en tant que service qui prend en charge les scientifiques des données.
- Analyse des données : Construire des modèles, transformer des prototypes en solutions opérationnelles.
La science des données (Data Science) est aussi un développement. Le scientifique des données doit écrire du code et tester les résultats afin de trouver une solution, et cette solution doit être opérationnalisée / automatisée.
Voici d’autres exemples de composants DevOps qui s'appliquent aux DataOps :
- Le contrôle de version permet aux équipes de développement de suivre et de contrôler les changements dans l'infrastructure de données, à travers différentes versions et périodes de temps. Cela rationalise la révision, la réversion et le débogage.
- L'intégration continue (CI) intègre le code du développeur avec une branche de code principale.
- Les tests automatisés effectuent des tests automatisés sur la nouvelle infrastructure de données pour fournir à l'équipe un retour immédiat, y compris des tests unitaires, des tests fonctionnels ainsi que des tests de bout en bout (et des tests de sécurité !)
- La livraison continue (CD) garantit la qualité et la cohérence. Cela permet d'éviter les bugs et les interruptions pour les utilisateurs.
- Le déploiement continu (CD) pousse automatiquement la nouvelle infrastructure de données en direct, dans l'environnement de production, idéalement lors de petits changements fréquents
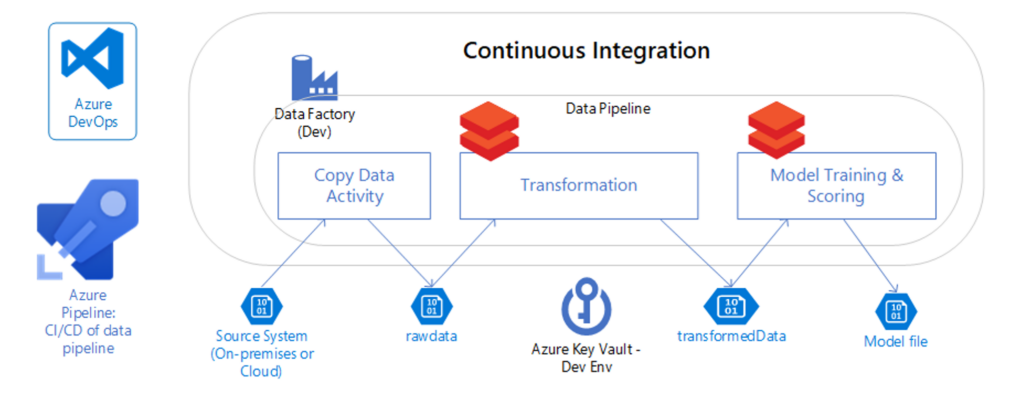
Les bénéfices et cas d'usage du DataOps
Cela démontre clairement pourquoi les entreprises Big Data s'appuient de plus en plus souvent sur les pratiques DevOps et impliquent des spécialistes des données au sein des processus CI/CD. Les avantages en sont les suivants :
Une planification plus efficace des mises à jour logicielles
Il faut dire que la plupart des logiciels interagissent avec les données d'une manière ou d'une autre. Lorsque vous mettez à jour ou reconcevez une application, vous voulez avoir la compréhension la plus précise possible des types de sources de données avec lesquelles votre application fonctionnera.
Des taux d'erreur inférieurs
En effet, les problèmes de gestion des données peuvent être une source importante d'erreurs lors de l'écriture et du test du logiciel. Plus votre application et les données avec lesquelles elle fonctionne sont complexes, plus le risque d'erreurs est élevé.
Trouver ces erreurs au début du pipeline de livraison de logiciels (ou, mieux encore, les éviter en premier lieu) permet d'économiser du temps et des efforts. (Il s'agit du principe DevOps du « shift-left », qui met l'accent sur les tests précoces des modifications de code). On minimise donc ces risques grâce à des tests continus dès les premières étapes.
Une collaboration étroite entre les experts en données et le reste de l'équipe DevOps est alors cruciale en cas de problème pour trouver et corriger les erreurs liées aux données dans une application.
Une meilleure cohérence entre les environnements de développement et de production
Le mouvement DevOps souligne l'importance de faire en sorte que les environnements de développement soient identiques aux environnements de production.
En étant impliqués tout au long du processus de livraison du logiciel, les experts en données peuvent aider le reste de l'équipe à comprendre les types de problèmes de données auxquels leur logiciel sera confronté en production. La collaboration entre les équipes Big Data et DevOps conduira ainsi à des applications dont le comportement réel correspond le plus possible à son comportement dans les environnements de développement et de test.
Un retour plus précis de la production
La dernière partie du processus de livraison continue consiste à collecter des données à partir de votre environnement de production après la sortie de votre logiciel.
En apportant leurs compétences en analyse de données au processus de rétroaction DevOps, les experts en données peuvent s'assurer que l'organisation a la meilleure compréhension possible de ce qui fonctionne et de ce qui ne fait pas partie de la chaîne de livraison continue DevOps.
De la précision dans la rétroaction
Une fois qu'une application ou un logiciel est produit et publié, certaines données sont collectées. Ensuite, ces données sont analysées et les équipes déterminent quelle partie du logiciel fonctionne bien (ou pas).
Ces données sont utiles car elles constituent une base pour la prochaine mise à jour du logiciel/de l'application. Les données collectées pour l'analyse incluent la santé de l'application et de l’infrastructure sous-jacente grâce à des outils d’observabilité.
Les processus sont automatisés
L’approche DevOps permet effectivement d’automatiser la migration et la traduction de données, ou encore d’améliorer la qualité des données.
Une analyse continue est fournie
Votre projet bénéficiera d'une autre pratique DevOps utile telle que l'analyse continue, qui rationalise les processus d'analyse des données et les automatise via des algorithmes.
DataOps vs DevOps : deux domaines qui partagent les mêmes principes de développement et de déploiement.
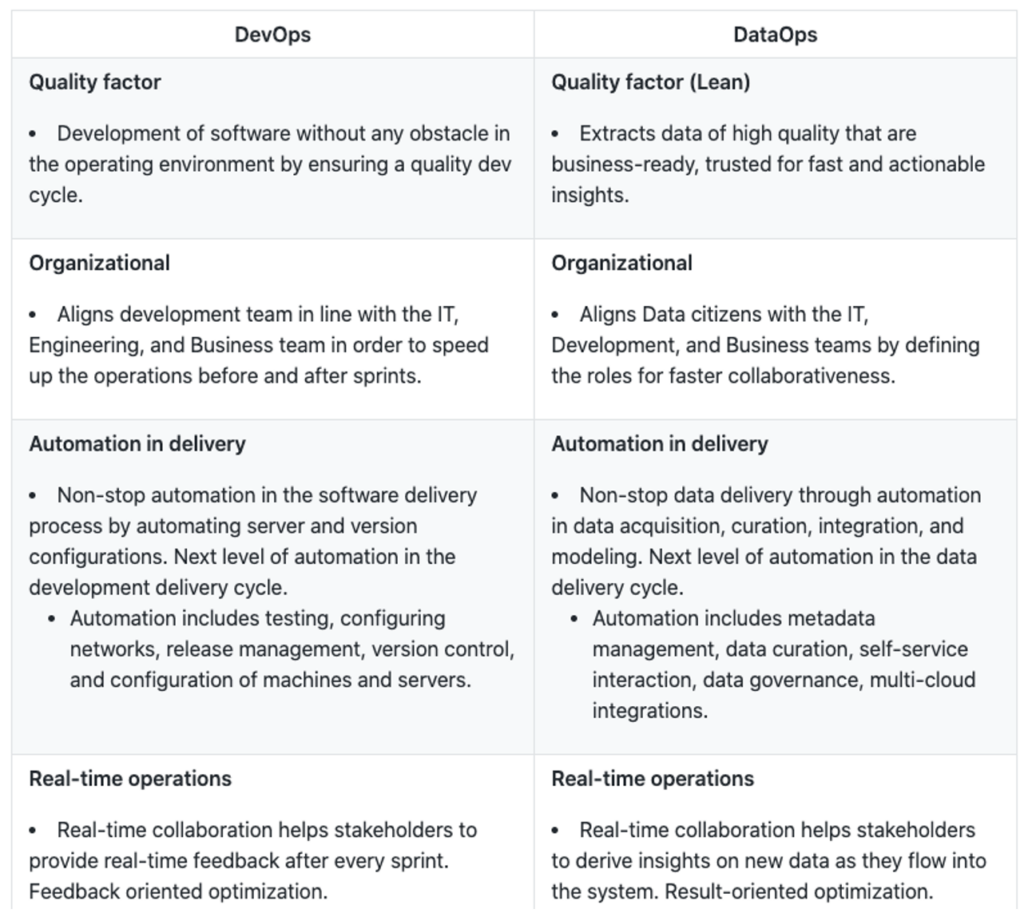
Alors que l'économie devient encore plus orientée sur les données et que les besoins augmentent rapidement, les équipes de données ne peuvent pas simplement compter sur la technologie pour rester compétitives.
En exploitant le DevOps, le DataOps injecte les meilleures méthodes et pratiques de développement logiciel dans le processus d'orchestration des données, permettant la livraison, rapide et de qualité, des données.
C'est pour cela que le DataOps a besoin des principes du DevOps, pour fournir aux parties prenantes des données de manière rapide et efficace.