Face à la pénurie de profils IT et à l’accélération technologique, de plus en plus de DSI misent sur le développement interne.
Mais « former ses équipes » recouvre différentes approches, comme l’upskilling, le reskilling ou la mise en place d’une academy interne.
Cet article s’appuie sur notre livre blanc « Vers la DSI de 2027 : construire son plan de formation » et explique en quoi ce sont trois modèles distincts, avec des logiques, des durées et des conditions de réussite très différentes.
Comprendre ces distinctions est le prérequis pour choisir la bonne approche selon votre contexte.
La transformation IT imposée par le cloud hybride, l’IA et la cybersécurité oblige les entreprises à dépasser les formations ponctuelles.
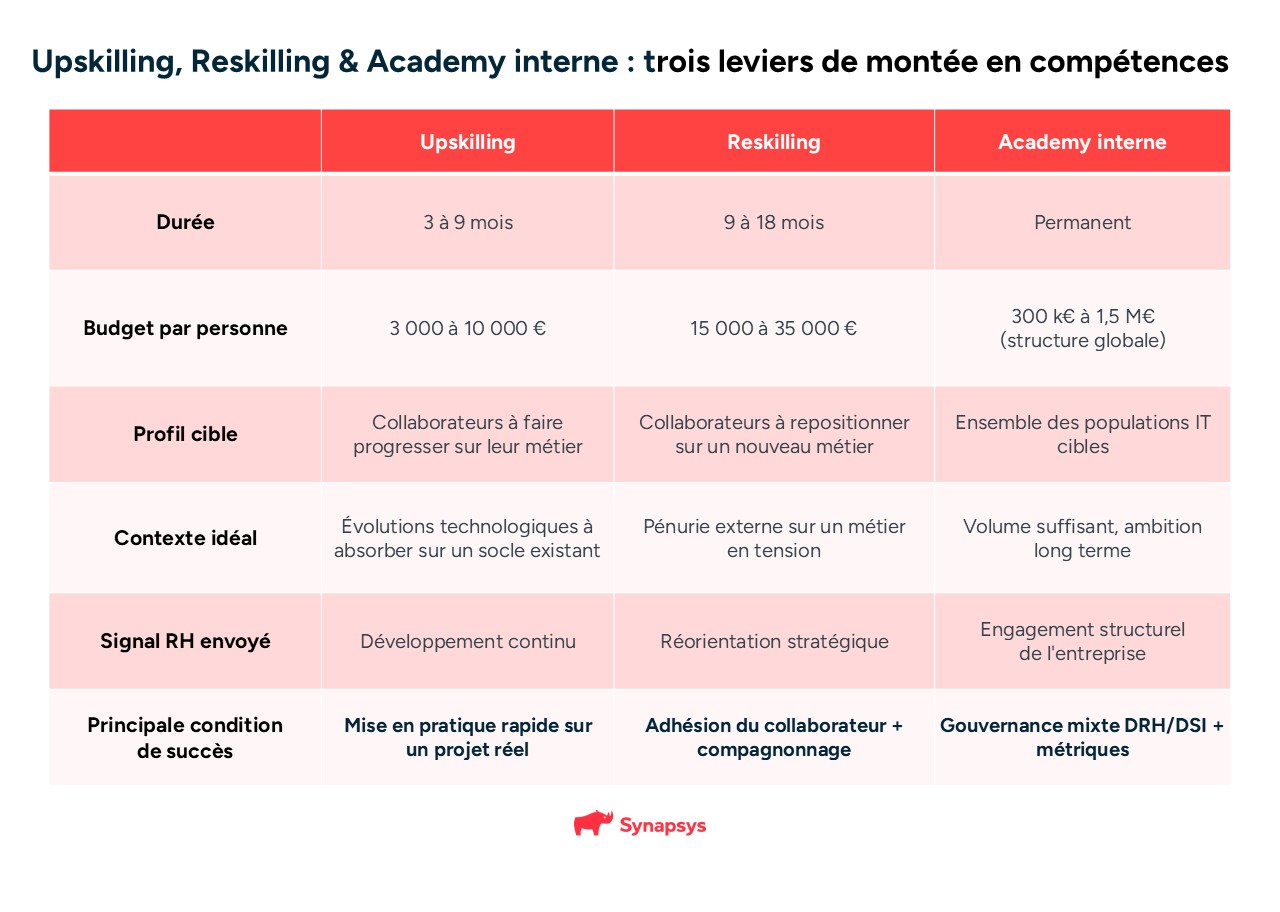
Mais « former » peut vouloir dire des choses très différentes selon la situation :
Confondre ces trois logiques, c’est risquer d’appliquer le mauvais outil.
Par exemple : un upskilling là où il faudrait un reskilling structuré, ou vouloir créer une academy interne sans les conditions organisationnelles qui la rendent viable.
L’upskilling consiste à développer les compétences d’un collaborateur dans la continuité de son métier actuel.
Le périmètre professionnel ne change pas : c’est le niveau technique et l’étendue des compétences qui progressent.
Exemples concrets :
L’upskilling est adapté lorsque l’entreprise dispose d’une base solide de collaborateurs IT expérimentés qu’il s’agit de faire évoluer pour suivre des ruptures technologiques bien identifiées.
C’est le levier le plus courant, le plus rapide à mettre en œuvre, et le moins risqué organisationnellement.
Il est particulièrement pertinent sur les 8 familles de compétences IT critiques pour 2027 (cloud, DevOps, cybersécurité, automatisation, IA appliquée à l’IT) où les technologies évoluent vite mais où le socle métier des collaborateurs reste un atout réel.
Durée typique : 3 à 9 mois.
Budget : 3 000 € à 10 000 € par personne.
Ce budget intègre la formation certifiante, les temps de pratique encadrés et les éventuels frais de certification.
Il peut être significativement réduit via les dispositifs de financement disponibles (OPCO, plan de développement des compétences, CPF co-construit).
Une formation certifiante non suivie d’une application concrète dans les 3 mois qui suivent perd 80 % de sa valeur.
Tout parcours d’upskilling doit prévoir, en amont, le projet ou le contexte dans lequel la personne va appliquer ses nouvelles compétences.
Sans ce prérequis, la certification devient un trophée, pas un levier de valeur.
Le reskilling consiste à faire basculer un collaborateur d’un métier vers un autre, parfois très éloigné.
Ce n’est pas une montée en niveau : c’est une transformation profonde du métier exercé.
Exemples typiques :
Le reskilling répond à une situation précise : des métiers en tension extrême pour lesquels le marché externe ne fournit pas de profils (cybersécurité opérationnelle, FinOps, IA appliquée à l’IT, Platform Engineering) combinés à l’existence d’un vivier interne motivé.
Il répond aussi à une réalité démographique.
Certains métiers IT évoluent si profondément (exploitation traditionnelle, administration on-premise classique) que les collaborateurs qui les exercent peuvent, avec un accompagnement structuré, être repositionnés sur des métiers d’avenir plutôt que d’être laissés en marge de la transformation.
Durée typique : 9 à 18 mois.
Budget : 15 000 € à 35 000 € par personne.
Ce budget peut paraître élevé, mais il se compare directement au coût d’un recrutement externe senior (entre 30 000 € et 80 000 € toutes charges comprises : salaire, honoraires de cabinet, onboarding, perte de productivité).
Une reconversion interne complète coûte donc souvent moins cher qu’un seul recrutement, tout en renforçant la fidélité et la culture d’entreprise.
L’adhésion du collaborateur est non négociable.
Un reskilling imposé sans motivation échoue presque systématiquement.
L’envie d’évoluer vers le nouveau métier doit être identifiée et confirmée avant d’engager l’investissement.
Un parcours structuré avec des jalons clairs :
Le compagnonnage avec un expert senior, qui permet d’ancrer les nouvelles compétences dans le contexte réel de l’entreprise dès les premières semaines, avant même la fin du parcours formel.
Une academy interne est un dispositif structurel qui regroupe sous une marque interne les parcours de formation stratégiques d’une entreprise.
Elle peut inclure de l’upskilling et du reskilling, mais y ajoute une dimension de permanence, de visibilité et de culture d’apprentissage collective.
La différence essentielle : les collaborateurs ne suivent pas des formations isolées.
Ils rejoignent un programme identifiable, avec ses promotions, ses certifications internes, ses rituels (cérémonies de lancement, revues de mi-parcours, remises de diplômes).
L’academy n’est pas un catalogue de formations déguisé sous un nom de marque : c’est un dispositif avec une gouvernance, des métriques et une ambition de long terme.
Les entreprises qui ont créé une academy constatent une réduction du turnover de 20 à 30 % sur les populations concernées.
L’academy envoie un signal fort aux collaborateurs : leur développement est un engagement de l’entreprise, pas une promesse.
Or les profils IT quittent souvent leur entreprise non parce qu’ils sont mal payés, mais parce qu’ils ne voient pas comment progresser.
Avec 68 % des décideurs IT qui font du déploiement de l’IA une priorité 2026 et 52 % qui reconnaissent que leurs équipes ne sont pas prêtes, la formation au cas par cas ne suffit plus.
Une academy permet de former vite, en masse, avec une cohérence pédagogique.
Les promotions avancent ensemble, se soutiennent mutuellement, et la culture d’apprentissage devient un réflexe collectif plutôt qu’un effort individuel.

Sur un marché IT en tension, « nous avons une academy interne » devient un argument décisif lors du recrutement, notamment pour les profils juniors et mid-career sensibles à la promesse de développement continu.
Le bouche-à-oreille IT devient un atout d’attraction.
L’academy permet d’institutionnaliser la transmission :
C’est une réponse structurante au défi des départs à la retraite de profils porteurs d’une mémoire technique irremplaçable.
L’academy est adaptée aux grandes entreprises ou ETI disposant d’un volume suffisant de collaborateurs IT, avec une ambition de long terme et la volonté de faire de la formation un pilier de la marque employeur.
Des structures plus modestes peuvent néanmoins initier des academies ciblées sur 2 ou 3 familles de compétences prioritaires, avec une gouvernance allégée.
Une academy interne ne se résume pas à un nom de marque apposé sur un catalogue de formations existant.
Pour produire un réel impact sur la montée en compétences et la fidélisation des équipes IT, elle doit reposer sur une architecture précise :

Les formations sont souvent achetées sans lien avec la roadmap.
Les collaborateurs sortent enthousiastes et retournent à leurs tâches sans jamais appliquer.
La skill gap analysis doit produire une stratégie (pour chaque compétence critique, un choix clair entre internaliser, externaliser ou hybrider) pas une liste de formations.
Empiler les certifications sans vérifier la mise en pratique n’est pas utile.
Dans un bon plan de formation IT, chaque certification est couplée à un projet d’application réel dans les 3 à 6 mois qui suivent.
Les profils IT critiques pour 2027 combinent une palette technique large et des soft skills solides :
Un expert qui ne sait pas parler au métier ou porter un projet reste sous-exploité, quelle que soit sa maîtrise technique.
En outillant les seniors à la transmission avant qu’ils partent.
Former uniquement les juniors sans capitaliser les connaissances des profils expérimentés, c’est prendre le risque de voir des pans entiers de mémoire technique disparaître à chaque départ.
Réinventer toutes les formations en interne est une erreur fréquente.
Les partenaires externes apportent une veille technologique et une expertise difficiles à maintenir à jour par les équipes internes.
L’équilibre interne/externe est la clé d’un plan de formation IT efficace et durable.