AWS Summit Paris 2026 : l’IA agentique, nouveau standard du cloud
AWS Summit Paris 2026 et IA agentique : l’IA agentique entre en phase d’industrialisation. La question n’est plus de savoir...


AWS propose plus de 200 services couvrant le calcul, le stockage, les bases de données, la sécurité et l’intelligence artificielle. Bien les choisir ne relève pas uniquement des équipes techniques : c’est une décision stratégique qui engage les budgets, la sécurité des données et la capacité de l’organisation à faire évoluer son infrastructure dans la durée.
Choisir entre un service managé et une infrastructure administrée en interne engage trois variables simultanément : le coût à la facture, la charge opérationnelle des équipes IT, et la capacité à faire évoluer l’infrastructure dans la durée.
Un service très automatisé réduit les efforts humains, mais pèse souvent plus lourd sur le budget. Ces arbitrages dépassent les équipes techniques : ils engagent les budgets, la conformité et la trajectoire cloud de l’organisation.
Pour un décideur, le risque est double. Ne pas adopter les bons services freine la transformation numérique et laisse les équipes gérer manuellement des tâches qu’AWS automatise bien.
À l’inverse, adopter des services sans cadre clair conduit à des factures qui explosent, des problèmes de conformité non anticipés, et une dépendance croissante envers un fournisseur unique.
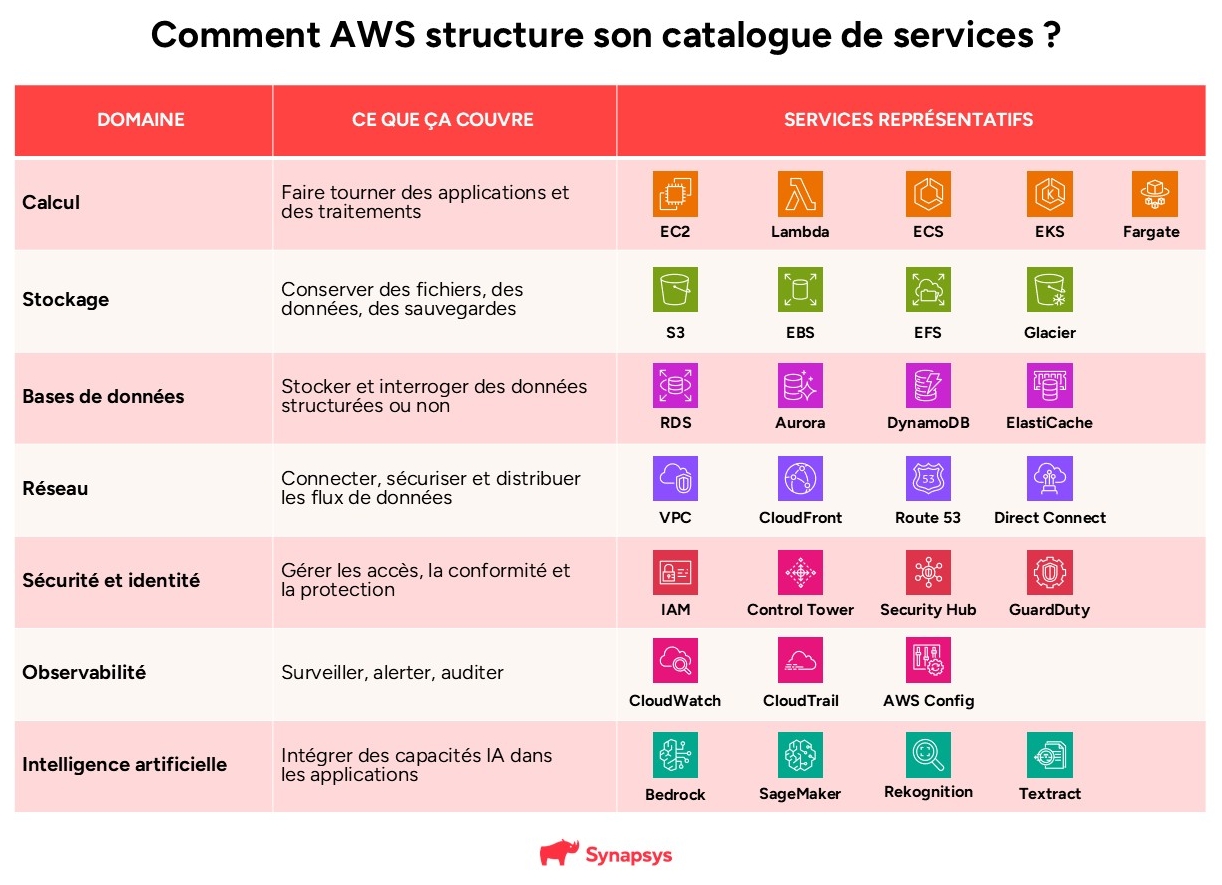
Avant de choisir un service, il est utile de comprendre comment AWS structure son offre. Le catalogue s’organise en grands domaines fonctionnels, chacun couvrant une famille de besoins distincts.
Identifier dans quel domaine s’inscrit un projet permet de cadrer rapidement les services à évaluer, et ceux à ne pas évaluer :
Le catalogue AWS s’est encore élargi ces dernières années, notamment autour de l’intelligence artificielle avec Amazon Bedrock et les outils d’analyse de données. Cette richesse est un avantage réel, mais elle génère aussi une complexité de choix que les équipes IT peinent parfois à absorber seules.
Le contexte réglementaire ajoute une contrainte concrète. Le RGPD impose des règles sur la localisation des données en Europe, ce qui influe sur le choix des régions AWS.
En France, les secteurs de la santé et des services publics font face à des exigences de souveraineté numérique qui peuvent imposer des architectures hybrides ou restreindre certains services cloud américains. Ces contraintes doivent être intégrées dès la conception, et non découvertes lors d’un audit.

AWS fonctionne selon un principe de responsabilité partagée : AWS s’occupe de la sécurité de l’infrastructure physique (datacenters, câbles, serveurs). La façon dont les applications et les données sont configurées, protégées et accessibles reste en revanche de la responsabilité du client.
Concrètement, une entreprise qui ouvre un service cloud sans en restreindre correctement les accès expose ses données, même si l’infrastructure AWS elle-même est parfaitement sécurisée.
L’enjeu est de comprendre où s’arrête la responsabilité d’AWS et où commence la vôtre, pour dimensionner les équipes en conséquence.
Les applications telles que les ERP, CRM ou bases de données transactionnelles ont besoin d’une disponibilité constante. Elles bénéficient de serveurs dédiés (comme Amazon EC2 ou Amazon RDS) avec des engagements tarifaires longue durée (un ou trois ans) qui peuvent générer des économies par rapport à un paiement à l’usage.
Ils tirent parti de services qui ne fonctionnent, et ne coûtent, que lorsqu’ils sont sollicités. C’est le principe du « serverless » avec AWS Lambda : on paie à l’usage réel, à la milliseconde d’exécution. Ce modèle convient aux APIs légères, aux automatisations déclenchées par événement ou aux traitements de fichiers, à condition que la durée d’exécution reste inférieure à 15 minutes.
Les plateformes e-commerce lors des pics de vente, les SaaS ou les applications mobiles nécessitent des architectures capables de s’adapter automatiquement au volume. AWS propose pour cela des mécanismes d’auto-scaling : les ressources s’ajustent à la demande sans intervention manuelle, et la facturation suit l’usage effectif.
L’erreur la plus courante est d’appliquer le même modèle d’infrastructure à toutes les applications. Cela revient à louer un camion pour faire ses courses quotidiennes : efficace à l’occasion, coûteux en usage permanent.
Le cloud permet de démarrer rapidement, mais sans règles claires, la facture croît plus vite que l’usage réel. Les cinq leviers principaux sont les suivants :
Sans gouvernance, les équipes créent des ressources sans convention de nommage ni rattachement à un budget. Quelques mois plus tard, personne ne sait plus à quoi correspond tel serveur. La facture devient une boîte noire.
La bonne pratique est de définir dès le départ un système d’étiquetage des ressources : le « tagging ». Chaque serveur, base de données ou service doit être associé à un projet, une équipe et un centre de coût.
AWS propose des outils natifs pour consolider cette vision et alerter en cas de dérive budgétaire, à condition que les ressources soient correctement étiquetées :
| Solution AWS | Usage cible | Points forts | Limites | Profil recommandé | Critère de choix |
| Amazon EC2 | Applications standards, migration on-premise | Contrôle total, large choix de configurations | L’équipe gère le serveur : mises à jour, sécurité | Organisations avec équipes IT solides | Contrôle fin du système nécessaire |
| AWS Lambda | Traitements ponctuels, APIs légères | Facturation à l’usage, aucun serveur à administrer | Pas adapté aux traitements longs ou continus | Équipes DevOps, projets d’intégration | Durée < 15 min, charge irrégulière |
| Amazon ECS | Conteneurs sans expertise Kubernetes | Plus simple qu’EKS, natif AWS | Moins portable qu’EKS | Équipes voulant des conteneurs sans complexité Kubernetes | Conteneurs managés, sans expertise Kubernetes |
| Amazon EKS | Applications conteneurisées à grande échelle | Flexibilité, portabilité multi-cloud | Complexité élevée, expertise spécifique requise | Organisations avec équipes techniques avancées | Portabilité requise, nombreux microservices |
| Amazon RDS / Aurora | Bases de données relationnelles (CRM, ERP) | Haute disponibilité, sauvegardes automatisées | Moins flexible qu’une BDD auto-hébergée | Toutes organisations, bon point de départ | Données relationnelles classiques, équipe SQL |
| Amazon DynamoDB | Applications à fort volume, données flexibles | Scalabilité automatique, latence en millisecondes | Modèle de données différent des bases classiques | Applications web/mobile, IoT | Latence ms requise, schéma flexible |
| Amazon S3 + CloudFront | Stockage de fichiers, diffusion de contenus | Très fiable, économique, universel | Pas conçu pour remplacer un serveur de fichiers | Tous profils | Stockage objet ou diffusion de contenus statiques |
| Amazon Bedrock | Intégration d’IA générative | Accès à plusieurs modèles via une API unique | Moins adapté aux modèles propriétaires | Équipes ajoutant de l’IA sans gérer de modèles | Usage de modèles existants, sans entraînement |
| Amazon SageMaker | Entraînement de modèles IA personnalisés | Environnement complet pour les équipes data science | Complexité et coût élevés pour des usages simples | Équipes data science avec modèles propriétaires | Modèles IA à entraîner ou fine-tuner |
AWS EC2 : Déploiement de Weaviate sur AWS EC2 : une voie rentable vers le RAG de niveau entreprise
Conteneurs AWS : Arbitrez entre ECS, EKS et Lambda
AWS pour le DevOps : Tour d’horizon des outils et services
AWS IAM : Renforcer la sécurité et la gestion des identités dans le cloud
Amazon S3 Vectors : Object Serverless Vector Database
L’IA est devenue un sujet central dans les stratégies cloud, et l’AWS Summit Paris 2026 l’a confirmé : l’édition a placé l’IA agentique au cœur de toutes les sessions, tous secteurs confondus.
Pour les organisations françaises, ce signal est concret : l’IA n’est plus un sujet exploratoire, c’est une composante d’architecture à intégrer dès maintenant. Pour une organisation qui souhaite franchir ce pas, deux grandes options se distinguent sur AWS : Bedrock et SageMaker.
La règle de décision est simple : si l’objectif est d’ajouter une capacité IA à une application existante, Bedrock est le point de départ naturel. Si l’objectif est de construire un modèle sur mesure à partir de données propriétaires, SageMaker est l’environnement adapté.
Amazon Bedrock s’adresse aux équipes qui veulent exploiter des modèles d’IA déjà entraînés sans gérer l’infrastructure complexe que cela implique.
Il donne accès via une interface unifiée à plusieurs modèles reconnus, génération de texte, analyse de documents, traitement d’images.
Pour un décideur, l’avantage est clair : on ajoute de l’IA à un produit sans recruter des data scientists ni investir dans une infrastructure spécialisée.
Amazon SageMaker répond à un besoin différent : entraîner, ajuster et déployer des modèles propriétaires à partir de données internes.
Il s’adresse aux organisations avec des cas d’usage très spécifiques ou des contraintes de confidentialité fortes. C’est plus puissant, mais aussi plus coûteux et plus exigeant en compétences.

Lorsqu’une application est conçue pour fonctionner exclusivement avec des services propriétaires AWS, elle devient difficile à migrer vers un autre fournisseur ou vers une infrastructure interne.
Ce n’est pas nécessairement un problème si la stratégie cloud est clairement mono-AWS.
En revanche, si les priorités évoluent, rachat par un groupe avec une politique cloud différente, changement réglementaire, réévaluation des coûts, ce verrouillage peut générer des coûts de migration considérables.
Face à la pression des régulateurs européens, AWS a annoncé en 2024 des ajustements sur les frais de sortie de données pour les clients souhaitant changer de fournisseur.
C’est un signal positif, mais qui ne dispense pas d’une réflexion architecturale en amont. La méthode recommandée est de distinguer dès la conception ce qui relève de la logique métier, qui doit rester portable, de ce qui relève de l’infrastructure AWS.
Avant de choisir un service AWS, caractériser l’application : est-elle critique ? Continue ou par pics ?
L’AWS Well-Architected Framework offre une grille de lecture structurée pour cet exercice.
Six critères à évaluer : sécurité, fiabilité, performance, coûts, excellence opérationnelle, durabilité.
Un outil gratuit dans la console AWS guide cet audit et identifie les risques avant qu’ils ne deviennent des incidents.
L’AWS Pricing Calculator permet de simuler la facture mensuelle. Comparer systématiquement trois scénarios : paiement à l’usage pur, engagement un an, engagement trois ans.
L’écart justifie une décision éclairée plutôt qu’un choix par défaut.
Définir la convention de tagging (projet, environnement, équipe, centre de coût) avant le premier déploiement. Revenir dessus après coup est long et rarement complet.
Activer les services de surveillance natifs AWS pour détecter automatiquement les mauvaises configurations et les accès non autorisés. Ces outils alertent les équipes avant qu’un problème ne devienne un incident.
Paramétrer des alertes budgétaires, analyser les recommandations AWS sur les ressources sous-utilisées, documenter les décisions prises. Sans cette routine, les coûts cloud dérivent naturellement à la hausse.
Déployer le même type de base de données ou de serveur pour toutes les applications, sans évaluer si d’autres options seraient plus adaptées, conduit à un surcoût structurel et à des performances inadaptées aux besoins réels.
Les échanges entre régions AWS ou vers Internet génèrent des frais invisibles lors de la conception. Dans des architectures complexes, ils peuvent représenter une part inattendue de la facture. Un poste « transfert de données » qui dépasse 15 % de la facture totale est un signal d’alerte à ne pas ignorer.
Des services comme Amazon EKS sont puissants mais exigent une expertise avancée. Les adopter sans les compétences internes ou l’accompagnement adéquat génère des coûts de support et des risques opérationnels difficiles à anticiper, et encore plus à diagnostiquer en production.
Déployer une application sur plusieurs datacenters AWS améliore la disponibilité en cas de panne matérielle, mais ne protège pas contre une panne applicative ou une corruption de données. Une infrastructure bien conçue doit être testée régulièrement en conditions de défaillance simulée, sans quoi un SLA peut ne pas être tenu malgré une architecture apparemment robuste.
Un service managé est un service dont AWS prend en charge l’administration courante : mises à jour, sauvegardes, disponibilité, scalabilité.
L’équipe IT n’a pas à s’occuper du serveur sous-jacent. Pour la plupart des organisations, les services managés réduisent la charge opérationnelle et améliorent la fiabilité, au prix d’une facture parfois plus élevée.
AWS convient à la grande majorité des entreprises, des startups aux grands groupes. La vraie question n’est pas « faut-il choisir AWS ? » mais « comment structurer son adoption ? ».
Les organisations qui échouent sur AWS le font généralement par manque de gouvernance, de formation des équipes, ou d’alignement entre les choix techniques et les contraintes métier.
Quatre actions prioritaires :
Sans ce pilotage actif, les coûts tendent à croître indépendamment de l’évolution réelle des besoins.
La bonne pratique est de séparer les environnements (production, tests, développement) dans des comptes distincts. Cela facilite la gestion des droits d’accès, l’isolation en cas d’incident et la lisibilité des coûts.
Pour une petite organisation débutante, un compte unique peut suffire au démarrage, à condition d’évoluer vers un modèle multi-comptes dès que l’usage se développe.
Bedrock pour accéder à des modèles existants sans gérer l’infrastructure IA. SageMaker pour entraîner ou ajuster des modèles propriétaires.
Pour un premier projet, Bedrock est presque toujours le bon point de départ : il permet de valider un cas d’usage sans investissement lourd, avant d’envisager un modèle sur mesure si nécessaire.
Une migration « lift-and-shift » génère rapidement des bénéfices en flexibilité et en résilience, mais rarement en coûts à court terme. Les gains financiers significatifs arrivent lorsque les applications sont adaptées pour tirer parti des services AWS. Ce travail se fait en plusieurs itérations, généralement sur six à dix-huit mois.
Articles similaires
AWS Summit Paris 2026 et IA agentique : l’IA agentique entre en phase d’industrialisation. La question n’est plus de savoir...
Amazon S3 Vectors, annoncé récemment en avant-première, représente la première solution de stockage cloud avec support natif pour les vecteurs,...
L'AWS Summit Paris 2025 était centré sur l'intelligence artificielle, avec presque chaque session et annonce abordant comment l'IA transforme les...